Kombination von Tableau und Python für präskriptive Analytics mit TabPy



Dieser Blog-Beitrag wurde zuerst auf Medium veröffentlicht.
TabPy ist ein Python-Paket, mit dem Python-Code im Handumdrehen ausgeführt und die Ergebnisse in Tableau-Visualisierungen dargestellt werden können. Damit lassen sich auf schnelle Weise Anwendungen mit fortgeschrittener Analytics bereitstellen. Der kombinierte Ansatz von TabPy ermöglicht die Nutzung des Besten aus beiden Welten – branchenführende Datenvisualisierungsfunktionen unterstützt durch leistungsstarke Data-Science-Algorithmen. Ein großer Vorteil bei der Nutzung von Python-Algorithmen in Tableau besteht darin, dass Benutzer Parameter optimieren und deren Auswirkungen auf die Analyse in Echtzeit auswerten können, wenn das Dashboard aktualisiert wird.
Dafür nutzt TabPy hauptsächlich einen Eingabe/Ausgabe-Ansatz, mit dem Daten gemäß der aktuellen Visualisierung aggregiert und Optimierungsparameter an Python übertragen werden. Die Daten werden dann verarbeitet und die Ausgabe wird zur Aktualisierung der aktuellen Visualisierung zurück an Tableau gesendet. Angenommen, Sie benötigen den kompletten zugrunde liegenden Datenbestand für eine Berechnung, Ihr Dashboard stellt aber eine aggregierte Kennzahl dar, oder Sie möchten mehrere Aggregationsebenen gleichzeitig anzeigen lassen. Darüber hinaus möchten Sie vielleicht mehrere Datenquellen in einer einzelnen Berechnung nutzen, ohne die Reaktionsfähigkeit Ihres Dashboards zu beeinträchtigen.
In diesem Beitrag werde ich einen Ansatz erläutern, mit dem Sie das gesamte Leistungsvermögen von TabPy für die folgenden Szenarien nutzen können:
- Interaktion in Echtzeit: Sie benötigen eine Echtzeit-Benutzeroberfläche und möchten damit die Dauer der Verarbeitung und die Verzögerung zwischen einer Parameteränderung und der Aktualisierung der Visualisierung minimieren.
- Mehrere Aggregationsebenen: Sie möchten mehrere unterschiedliche Aggregationsebenen in Tableau-Dashboards darstellen, müssen aber alle Berechnungen auf der untersten Detailebene mit allen Informationen durchführen.
- Mehrere Datenquellen: Die Back-End-Berechnung beruht auf mehr als einer Datenquelle und/oder Datenbank.
- Daten werden zwischen Tableau und Python übertragen: Für jeden Optimierungsschritt ist eine erhebliche Anzahl an Daten erforderlich, sodass sehr viele Daten zwischen Tableau und dem Python-Back-End übertragen werden müssen.
Ein neuartiger TabPy-Ansatz für präskriptive Analytics: Schrittweise Anleitung
Für die Implementierung von TabPy müssen Sie, vorausgesetzt, dass sowohl Python als auch TabPy bereits installiert sind, drei Schritte ausführen:
- Den Entwurf eines Tableau-Dashboards vorbereiten
- Ein Back-End für Berechnungsroutinen in Python erstellen
- Das Tableau-Front-End, das dieses nutzt, erstellen
Zur Ausführung dieser drei Schritte habe ich ein Fallbeispiel für eine Komplexitätsreduktion durch die Optimierung des Produktportfolios entwickelt.
Fallbeispiel: Komplexitätsreduktion
Gegenstand der Optimierung ist ein B2B-Einzelhändler, der hauptsächlich durch Fusionen und Akquisitionen gewachsen ist. Aufgrund dieses anorganischen Wachstums muss der Einzelhändler ein hohes Maß an Komplexität bewältigen. Er ist auf mehreren Märkten tätig und sein Portfolio besteht aus Tausenden von Artikeln in verschiedenen Warengruppen und Unterwarengruppen. Die Situation wird außerdem dadurch verkompliziert, dass die Artikel an unterschiedlichen Produktionsstätten hergestellt werden.
Die Geschäftsleitung des Unternehmens möchte die Margen erhöhen und dafür die am wenigsten rentablen Artikel aus dem Sortiment nehmen, gleichzeitig aber weiter weniger ertragreiche Artikel verkaufen, um keine Marktanteile zu verlieren. Außerdem sollen die Anlagen in den Produktionsstätten weiterhin oberhalb eines bestimmten Zielwerts ausgelastet werden, da sich eine zu große Reduzierung negativ auf die Fixkosten jedes Werks auswirken würde.
Für dieses Beispiel sind Daten in Form einer Artikeldatenbank verfügbar, in der die jährlichen Stückzahlen, Kosten und Umsatzzahlen dokumentiert sind. Die Artikel sind darin hierarchisch in Warengruppen und Unterwarengruppen gegliedert.
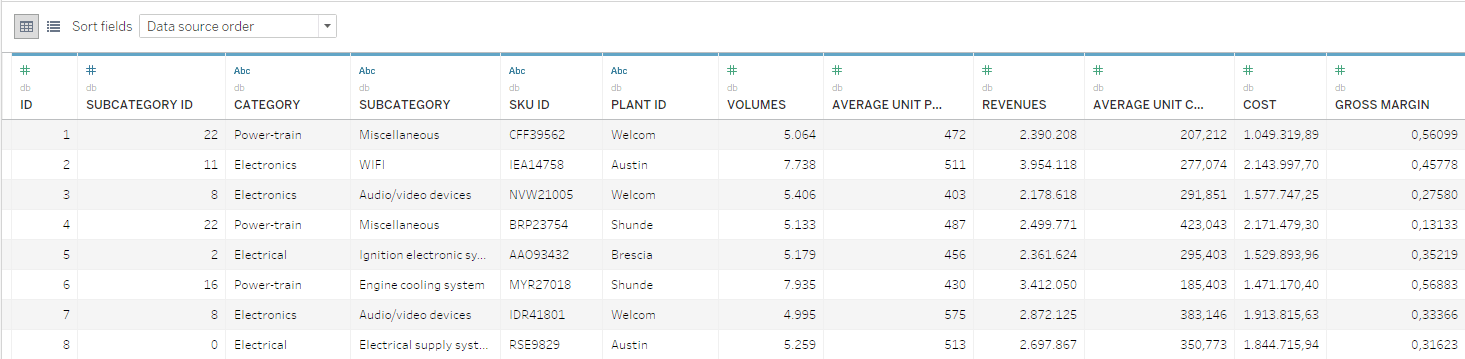
Aus mathematischer Sicht ist die Aufgabe der Optimierung des Produktportfolios recht unkompliziert. Für diese Optimierung müssen allerdings auch die gesamten strategischen Aspekte sowie eine breite Palette an Stakeholdern berücksichtigt werden, die Zugriff auf die Informationen und Tools haben, die sie für fundierte Entscheidungen benötigen.
Alle diese Anforderungen werden durch den im Folgenden beschriebenen TabPy-Ansatz erfüllt.
1. Entwurf eines Tableau-Dashboards vorbereiten
Zunächst muss eine Abstimmung auf das zu lösende Problem erfolgen. In diesem Beispiel entfernt der einfache Optimierungsalgorithmus Artikel gemäß der zugehörigen Bruttomarge, die auf Artikelebene ausgewertet wird.
-
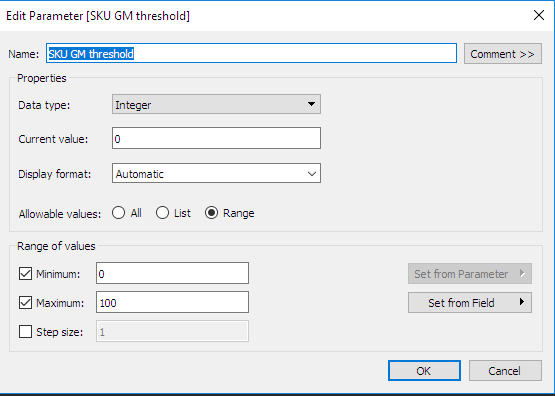
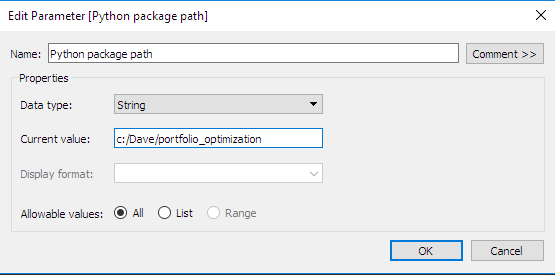
Definieren Sie die interaktiven Parameter in Tableau: Beachten Sie, dass wir zur Vereinfachung einen zweiten Parameter definiert haben. Dieser steht für das Verzeichnis, in dem das Python-Paket mit den Optimierungsroutinen gespeichert wird. Der Parametertyp ist sehr hilfreich für die Definition benutzerdefinierter Berechnungen, wie im nächsten Abschnitt gezeigt.
- Definieren Sie die Ansichten und Ebenen der Aggregation: In diesem Fall legen wir zwei Aggregationsebenen fest: eine Ebene für Artikel und eine Ebene für Unterwarengruppen. Die Definition der Aggregationsebenen spielt eine zentrale Rolle, da damit die Signaturen der Python-Back-End-Funktionen festgelegt werden. Für jede Berechnung und für jede Aggregationsebene muss eine eigene Funktion definiert werden. Außerdem müssen für jede Aggregationsebene folgende Parameter festgelegt werden: optimierte Margen, optimierter Umsatz und optimierte Stückzahlen.
-
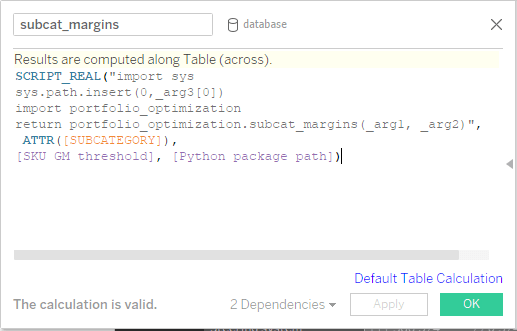
Definieren Sie Berechnungs-Hooks (Callbacks) in Tableau: Nachdem Eingabeparameter, Aggregationsebenen und die erforderlichen Ausgabeberechnungen definiert sind, können Sie benutzerdefinierte Berechnungen festlegen. Zur Vereinfachung wurden alle Optimierungsroutinen strukturiert in ein Python-Paket portfolio_optimization aufgenommen, in dem Funktionen zur Rückgabe der ausgewählten Mengen für die jeweiligen Aggregationsebenen definiert sind. Beachten Sie, dass der zuvor definierte Parameter – der Python-Paketpfad – an die Funktion übergeben wird und im Skript festlegt, wo das Paket zur Portfoliooptimierung gespeichert wird. Außerdem wird der aktuelle Indexer für die Aggregationsebene (z. B. für die Aggregationsebene der Unterwarengruppe oder für die Unterwarengruppe selbst) immer an das Python-Back-End übergeben, um sicherzustellen, dass die Ergebnisse in der richtigen Reihenfolge zurückgegeben werden. Außerdem wird der Eingabeparameter, also der Artikel-GM-Schwellenwert, übergeben.
2. Back-End für Berechnungsroutinen in Python erstellen
Das Python-Back-End ist in zwei Funktionsklassen aufgeteilt, die gemäß ihrem Ausführungstyp gruppiert sind: in einmal ausgeführte Funktionen und in Funktionen, die mehrmals ausgeführt werden. In der ersten Klasse sind z. B. ETL-Vorgänge für die Datenbank enthalten. Solche Funktionen werden als „einmalige Vorgänge“ bezeichnet. Im Gegensatz dazu gibt es Funktionen, die mehrfach ausgeführt werden, wie z. B. alle Tableau-Callbacks:
- Einmalige Vorgänge: In diesem Beispiel wird die Datenbank nur einmal geladen und zwar dann, wenn das Skript das erste Mal ausgeführt wird. Die Datenbank wird dann allen anderen Funktionen zur Verfügung gestellt, die sie in einer globalen Variable speichern. Um festzustellen, ob die Datenbank geladen ist, prüft Python den lokalen Namensbereich auf eine vorhandene Kopie davon. Ohne diese Maßnahme würde die Datenbank jedes Mal geladen werden, wenn von Tableau eine Berechnung angefordert wird. Dies hätte negative Auswirkungen auf die Ausführungsgeschwindigkeit.
- Tableau-Callbacks: Für jeden zuvor definierten Hook muss eine Funktion dafür vorhanden sein. Dies wird in unserem Fall durch Bereitstellung eigener Berechnungen für Umsatz, Stückzahlen und Margen sowie durch Verwendung des Indexers erreicht. Dieser wird als Eingabe der Funktion übergeben, um die groupby-Funktion von Pandas zu indexieren, mit der dann die Optimierungsergebnisse aggregiert werden. Beachten Sie, dass die Callbacks zur Verbesserung der Ausführungsgeschwindigkeit einen Detektor für die Parameteränderung implementieren. Eine neue Optimierung wird dann immer nur durchgeführt, wenn der Parameter geändert wird und sein Ergebnis für alle Callbacks verfügbar ist, die eine globale Variable nutzen. Die Ermittlung der Parameteränderung wird über eine persistente Variable implementiert, die den Parameterwert bei der vorherigen Ausführung speichert. Dieser Ansatz stellt sicher, dass nur die mindestens erforderliche Anzahl aufwändiger Vorgänge ausgeführt und so die Ausführungsgeschwindigkeit verbessert wird.
3. Tableau-Front-End entwerfen
Mit diesem Schritt haben wir alle grundlegenden Bausteine definiert, inklusive Aggregationsebenen, zu optimierende Parameter und vom Berechnungs-Back-End zurückgegebene Ausgabespalten.
Damit die Optimierung einfacher kommuniziert werden kann, definieren Sie am besten zwei verschiedene Arbeitsblätter, die das Portfolio einmal vor und einmal nach der Optimierung anzeigen. Stellen Sie die beiden Arbeitsblätter nebeneinander dar.
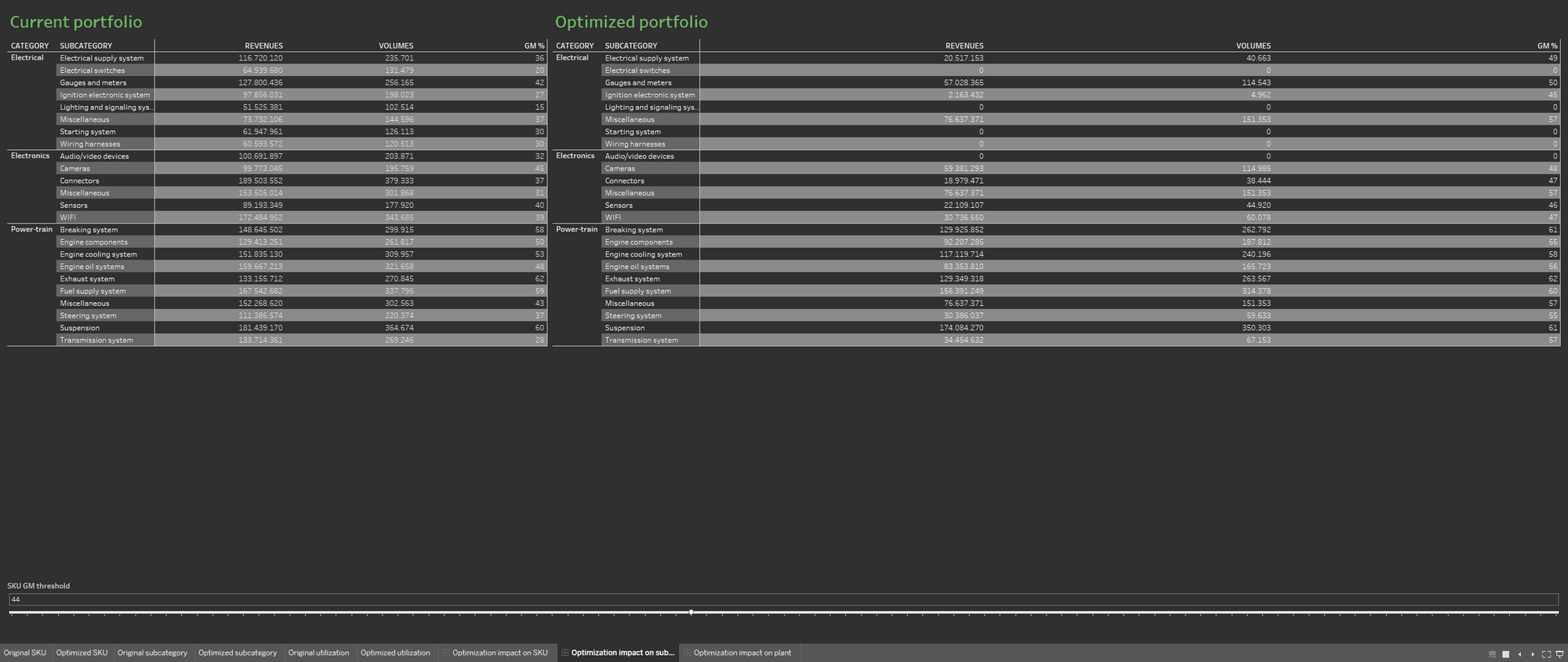
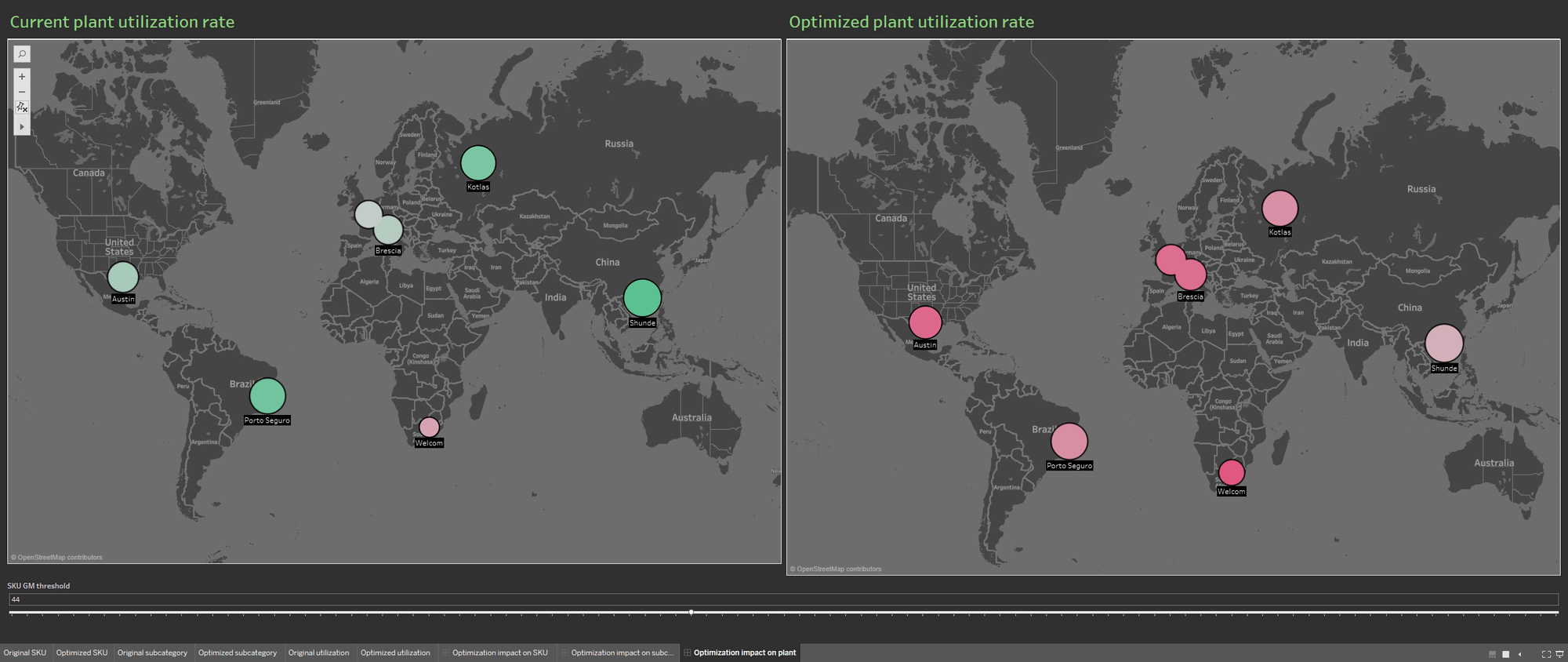
Durch Verfügbarkeit mehrerer Datenquellen wird die Portfoliodatenbank angereichert, da so Informationen über die aktuelle Rate der Anlagenauslastung und über die Rate aus dem optimierten Portfolio in die Visualisierung aufgenommen werden. Die beiden Visualisierungen der Informationen sollen wiederum nebeneinander dargestellt werden, um die Auswirkungen der Optimierung der Produktionsanlagen besser nachvollziehen zu können.
Weitere Vorteile der Verwendung von TabPy in Teams
Zusätzlich zu dem erheblichen Mehrwert für das Unternehmen, wenn Teams in die Lage versetzt werden, leistungsstarke Data-Science-Techniken interaktiv zu nutzen, bringt dieser neuartige Ansatz auch deutliche Vorteile für Back-Ends mit sich. Viele andere Techniken der Datenvisualisierung erfordern den kostspieligen Einsatz von Data Scientists im gesamten Prozess. Bei diesem Ansatz sind dagegen Data-Scientist-Ressourcen nur zum Vorbereiten des Entwurfs des Tableau-Dashboards und zum Erstellen der Python-Berechnungsroutinen für das Back-End notwendig. Die Benutzerfreundlichkeit von Tableau macht es möglich, dass sehr viel mehr Mitarbeiter unterschiedlicher Qualifikationen das Front-End entwerfen sowie mit den Endbenutzern testen und warten können.
Das Entwerfen des Designs eines Front-Ends ist in der Regel ein langwieriger und iterativer Vorgang, der viel Austausch mit den letztendlichen Benutzern erfordert. Mit dem neuartigen TabPy-Ansatz können aber die Führungskräfte das Team im Verlauf eines Projekts flexibel zusammenstellen und so die Kosteneffizienz erheblich verbessern. Dieser Ansatz garantiert auch eine hohe Wiederverwendbarkeit des zugrunde liegenden Back-Ends und ermöglicht einer breiten Palette an Benutzern das Erstellen eigener benutzerdefinierter Dashboards in Tableau, angepasst an den jeweiligen Kontext, an die Zielgruppe und an die Situation. Die Wiederverwendung der Berechnungslogik und der zugrunde liegenden fundamentalen Bausteine ist eine weitere Möglichkeit, die Gesamtkosten der Datenvisualisierung zu reduzieren.
Wenn Sie noch tiefer in dieses Beispiel einsteigen möchten, können Sie sowohl das Tableau-Dashboard als auch das Python-Back-End hier abrufen. Weitere Informationen zu diesem Ansatz finden Sie im offiziellen TabPy Github-Repository oder Sie rufen diesen Tableau Community-Thread auf.
Zugehörige Storys

How Team USA uses data to build a digital HQ
 8 Februar, 2022
8 Februar, 2022

Wichtige Datentrends für Sie in 2022
 3 Februar, 2022
3 Februar, 2022

Healthcare Analytics Hub Starter Kit: Get the data you need faster
 18 Oktober, 2019
18 Oktober, 2019
The purpose of the Healthcare Analytics Hub Starter Kit is to provide a sample of what your healthcare app could look like. It’s not a complete solution; instead, it’s focused on what’s possible. Please contact your Tableau Account Manager to get started today!
Blog abonnieren
Rufen Sie die neuesten Tableau-Updates in Ihrem Posteingang ab.