
自然言語処理に対応した Tableau の「データに聞く」機能は、Tableau Server または Online にパブリッシュされたデータソースのすべてと連携できるように構築されています。ただし、「データに聞く」機能のすべての利点を活用するには、最適な分析的会話をサポートするようにデータソースを適切に整理する必要があります。
優れたユーザーエクスペリエンスを実現するために、データソースの整理方法に関するガイドをご用意しました。「データに聞く」機能を組織に展開するのに役立ちます。https://www.tableau.com/ja-jp/ask-data
ユーザーの質問を理解する
「データに聞く」機能は、話し言葉での質問をいくつかの要素 (時間、空間、または数字表現を含むフレーズ) に分類し、コンテキストを活用してそのデータ型の属性を決定して、その意図を理解します。そして、ビジュアルベストプラクティスを使用して、ユーザーの意図を満たす最も適切なビジュアライゼーションを決定します。
たとえば、過去 1 年間の売上データを含んでいるパブリッシュされたデータソースに質問したいとします。「データに聞く」機能の入力ボックスに、「What is the profit over time? (経時的な利益は?)」という質問を入力できます。この場合、「データに聞く」機能は、既定の集計として「Profit (利益)」の合計を集計し、ユーザーの意図に対応します。 また、「時間」の意図をデータソースの「Order Date (注文日)」という属性として処理し、年レベルで集計します。
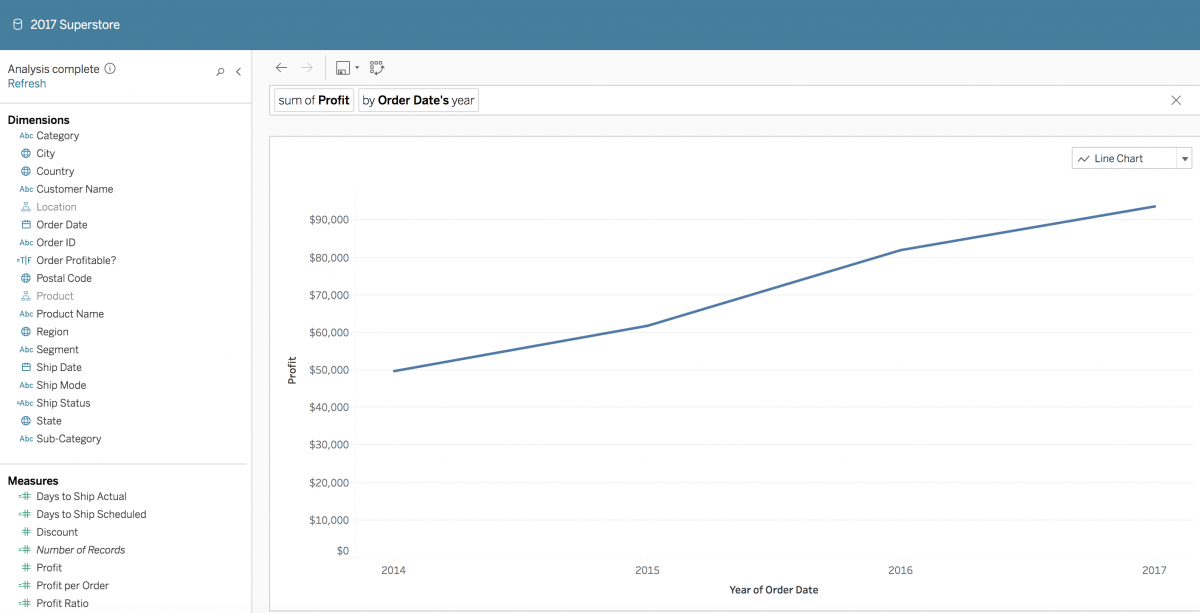
図 1: 「What is the profit over time? (経時的な利益は?)」という表現に対するビジュアライゼーション出力
「データに聞く」機能の推論アルゴリズムは、すべての属性が、予期されているデータ型である場合に最も効果的に機能します。この例では、予期されているデータ型は Date (日付) であり、これによって時系列のビジュアライゼーション (経時的なトレンド) が生成されます。予期されている既定の集計および数値形式でメジャーが指定される必要があります。
「データに聞く」機能を利用すれば、パブリッシュされたデータソースの計算フィールド、列フィールド、グループフィールド、ビンフィールドについて英語で質問できます。現在、「データに聞く」機能は、セット、パラメーター、結合フィールド、結合セット、階層はサポートしていません。これらのフィールドタイプについては、今後のリリースでサポートできるように進めています。
「データに聞く」機能でサポートされている分析的表現
分析的表現には 5 つの基本タイプがあります。話し言葉による質問はこれらの表現の 1 つまたは複数で構成されます。
次の分析的表現が「データに聞く」機能でサポートされています。
「データに聞く」機能には、たとえば降順を表す「from largest (大きいほうから)」や、平均を表す「mean (平均値)」といったコンセプトの一般的な同義語がいくつか組み込まれています。また、カウントの略語である「cnt」や、平均の略語である「avg」なども理解します。ユーザーが「データに聞く」機能に同義語を追加する方法については、こちらにアクセスしてください。
さらに、「データに聞く」機能は、絶対的または相対的な時間表現を理解します。つまり、「starts in (開始)」、「ends in (終了)」、「between (間)」などのの絶対時間概念の表現をサポートし、「last 3 years (過去 3 年間)」、「next quarter (次の四半期)」、「this month (今月)」、「today (今日)」、「yesterday (昨日)」などの相対時間概念の表現もサポートします。
最適な分析的会話のためにデータソースを準備する
「データに聞く」機能は、Tableau Server または Online にパブリッシュされたデータソースのいずれとも連携できるように構築されています。便利な既定値をフィルター表現に提供するために、「データに聞く」機能はフィールドに関するメタデータでセマンティックモデルを強化しています。連続する数値のメジャーのメタデータには、「minimum (最小)」、「maximum (最大)」、「average (平均)」など、統計情報が含まれています。テキストフィールドのメタデータには、最もよく使用される値が含まれています。
ユーザーが「データに聞く」機能にフィルター表現を入力すると、これらのメタデータによって値の提案が表示されます。たとえば、下図では属性「Price (価格)」とフィルター「at least (最小)」で、メタデータの最小値として「$4」が表示されています。
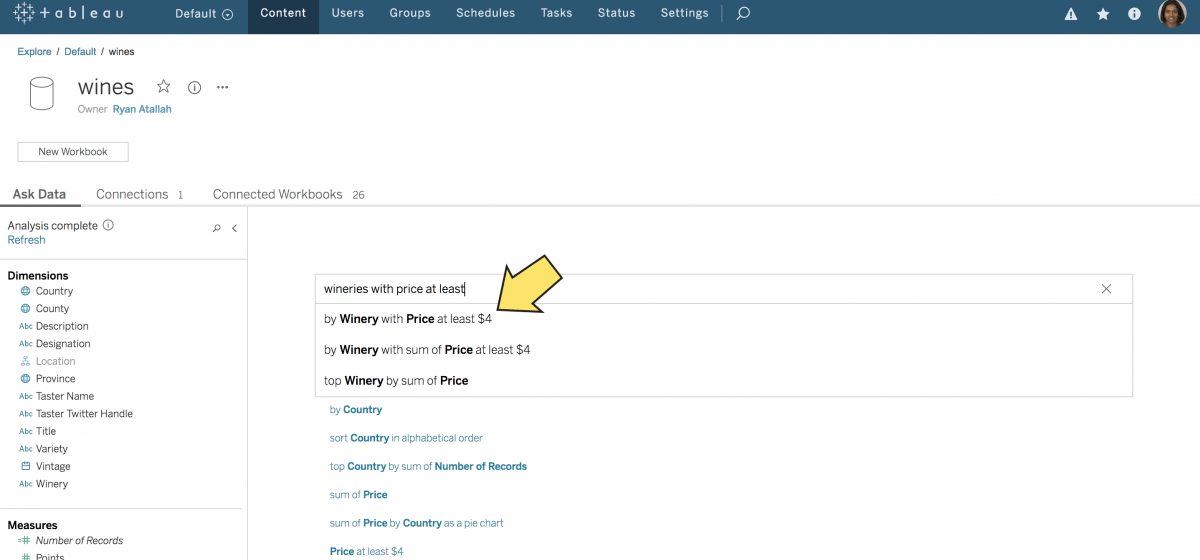
図 2: 「Price (価格)」の属性と「at least (最小)」のフィルターで、メタデータの最小値として「$4」が表示される。
データソースに行レベルのセキュリティが適用されている場合、「データに聞く」機能は、セマンティックモデルのフィールドについてプロファイルやインデックスを作成することも、メタデータを保存することもありません。「データに聞く」機能は、メタデータがないとフィルターの既定設定を提供できず (図 2 参照)、また「cheap (安い)」や「high (高い)」といった比較の概念を認識できないほか、データペインのツールヒントでプロファイルデータを表示できません。
しかし、一部のデータソースには、行レベルのセキュリティが適用されています。「データに聞く」機能では、そのようなデータソースのインデックスを作成することはできませんが、ユーザーがフィルタリングしたい値を正確に指定し、その値を引用符で囲むことで、「データに聞く」機能をうまく利用することはできます。
たとえば、「wineries in california that have pinot noir (カリフォルニア州でピノ・ノワールを扱っているワイナリー)」を表示させたいとします。データソースに行レベルのセキュリティが適用されていた場合は、「State (州)」と「Variety (取扱商品)」をフィルタリングするために、以下のように値を引用符で囲んで入力し、クエリを実行します。
日付、ブール、数字には、引用符は不要です。「データに聞く」機能がこれらの値を自動で認識し、対象にする適切なフィールドを判断します。
すでに認証済みのデータソースを組織向けにパブリッシュしている場合は、それらのソースを「データに聞く」機能で利用できます。ただし、エンドユーザーのために追加のソースを開いたり、「データに聞く」機能で簡単に分析するために既存のソースを形式変換したい場合があります。「データに聞く」機能を最大限に活用するためには、次のことを考慮してデータを整理してください。
エンドユーザーを念頭に置いてデータを整理する
分析に向けたデータの準備方法を理解し、ユーザーが自然言語を使ってデータについて聞く質問の種類を予測できるデータスチュワードやアナリストによってデータが慎重に整理されれば、「データに聞く」機能のユーザーが回答を得られる確率は非常に高くなります。
詳細については、パブリッシュされたデータソースの整理に関するベストプラクティスを確認してください。
「データに聞く」機能向けにデータを整理する場合は、パブリッシュされたデータソースをできるだけ簡素化することから始めましょう。つまり、ユーザーが「データに聞く」機能で実行するクエリの対象フィールドを最小限に抑え、不要なフィールドをデータソースから削除 (または非表示に) するということです。「データに聞く」機能は最大 1,000 フィールドのデータソースをサポートしますが、あいまいさが低いほど、より良い結果となります。これによって、イニシャライズ時間と自然言語による質問の分析がより迅速になり、システムパフォーマンス全体に貢献できます。データソースが遅い場合は、必要に応じてデータソースフィルターを使ってデータ抽出を行い、パフォーマンスを向上させましょう。
「データに聞く」機能でクエリを実行するためにデータソースを整理する場合は、次の要素を考慮してください。
データを準備する。ユーザーがデータソースから答えを得たい質問のタイプを予想するようにします。予想した質問への回答を得るためには、データ変換、結合操作、関連するデータ準備機能を使用して、データを適した形式に変換することが必要になる場合があります。
フィールドの適切な既定値を設定する。各フィールドに適切なデータ型 (文字列、数値、地理情報、日付、日付時刻、ブール) とデータフィールドの役割 (不連続または連続、メジャーまたはディメンション) を指定します。各メジャーには、既定の集計機能を割り当てます。たとえば、SUM は「Sales (売上)」には適切な既定値であり、AVERAGE は「Test Score (テストの点数)」に適切な既定値でしょう。
割合と通貨の数値形式を設定する。ユーザーがデータについて質問する時に使いがちな一般的な話し言葉の概念をサポートするために、「データに聞く」機能は「low (低い)」、「high (高い)」、「lowest (最低)」、「highest (最高)」などの概念や、「cheap (安い)」、「expensive (高い)」などの通貨ベースの概念、そしてそれらの同義語にも対応します。「show me the cheapest wineries in France (フランスで最も安いワイナリーを表示して)」のような話し言葉の質問をサポートするためには、データソースに適切な通貨形式でメジャーを設定しましょう (図 3 と 4 を参照)。
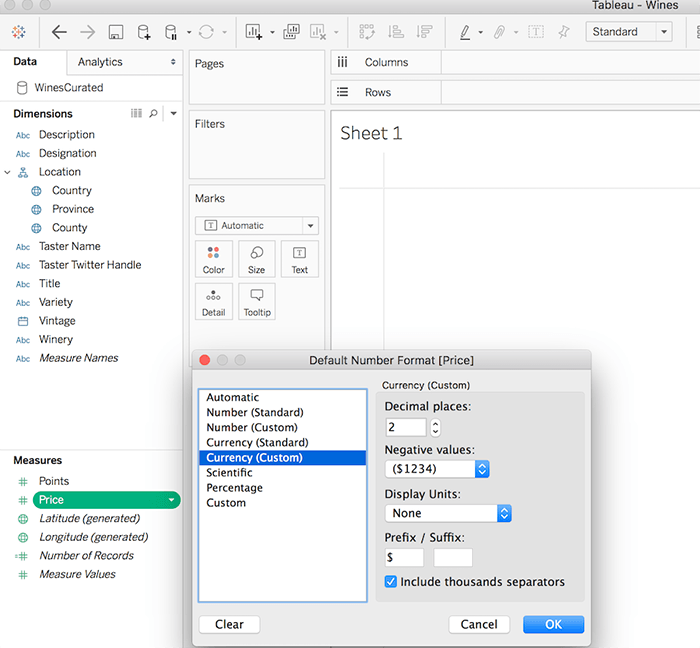
図 3: データソースに適切な通貨形式でメジャーを設定する。
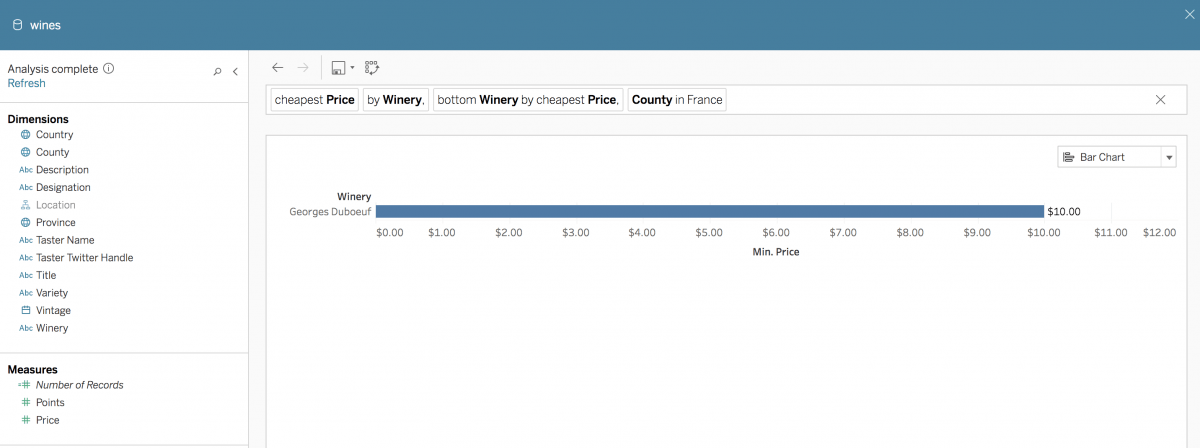
図 4: 話し言葉での質問「cheapest wineries in France (フランスで最も安いワイナリー)」について、システムは「cheapest (最も安い)」という概念に対し、通貨属性「Price (価格)」を推論する。「データに聞く」機能は、「Price (価格)」のメタデータから数値範囲を推論する。[cheapest (最も安い)] をクリックすると、推論された数値を絞り込める。
論理的階層の設定。これにより、ユーザーは「データに聞く」機能を使用して、生成されたビジュアライゼーションのドリルアップとドリルダウンができます。これは地理的ディメンション (City (市)、State (州)、Country (国) など)、日付と時刻 (year (年)、quarter (四半期)、month (月) など)、関数依存のディメンション (Category (カテゴリー)、Sub-category (サブカテゴリー) など) に当てはまります。
次のようなシナリオで、定量的な変化を知るために有効なのがビニングされたフィールドを (適切なビンサイズで) を作成することです。
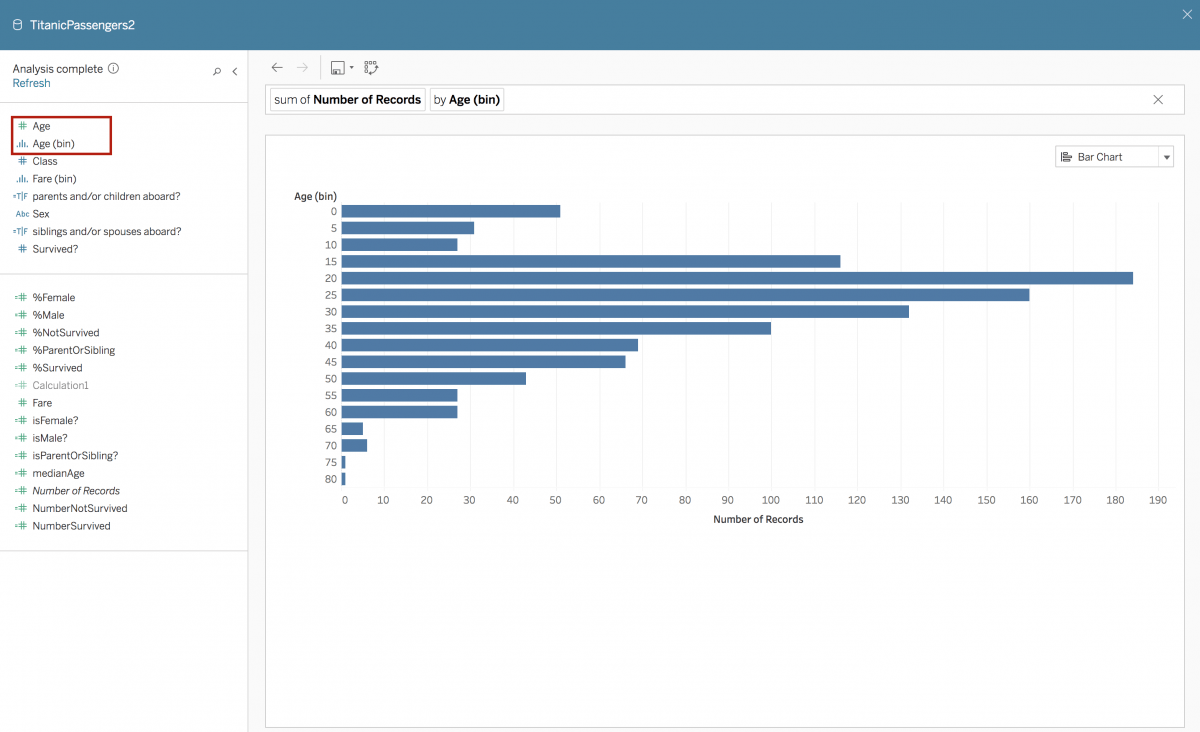
図 5: ユーザーは「by Age (bin) (年齢ごと (ビン))」と入力することで、ディメンションのビニング形式を棒グラフとして表示できる。
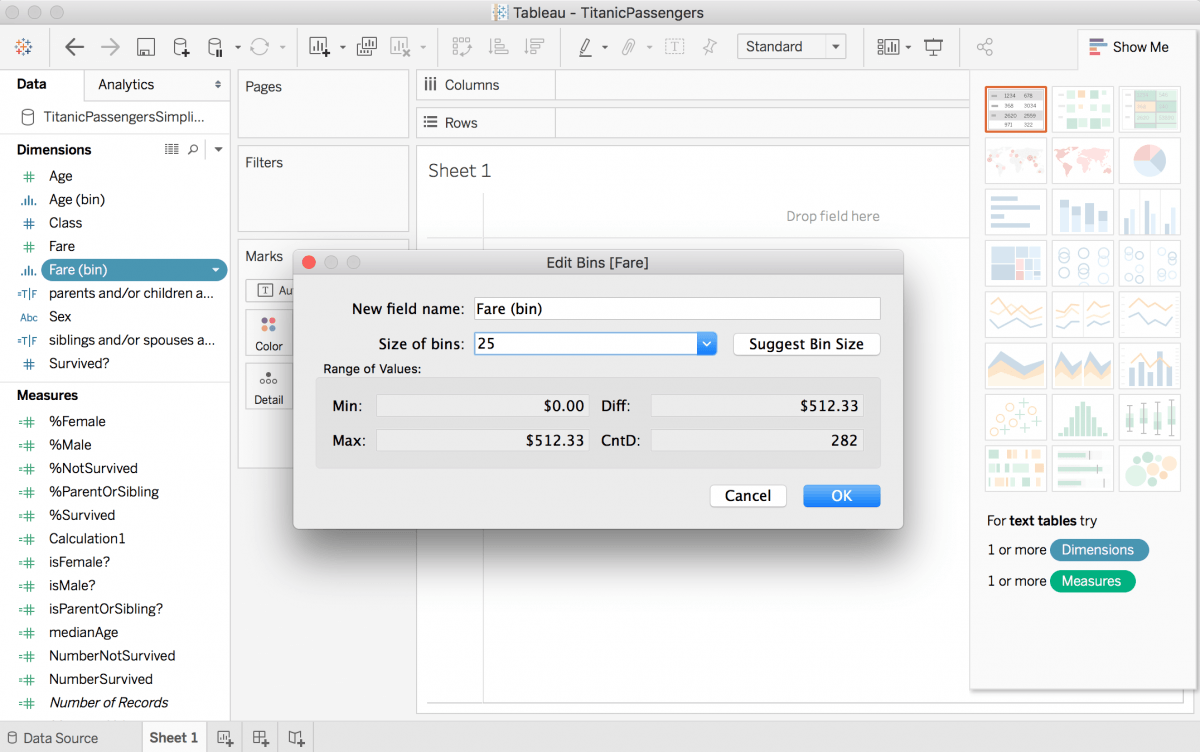
図 6: [データ] ペインで右クリック (Mac では Control を押しながらクリック) し、[作成] > [ビン] を選択。
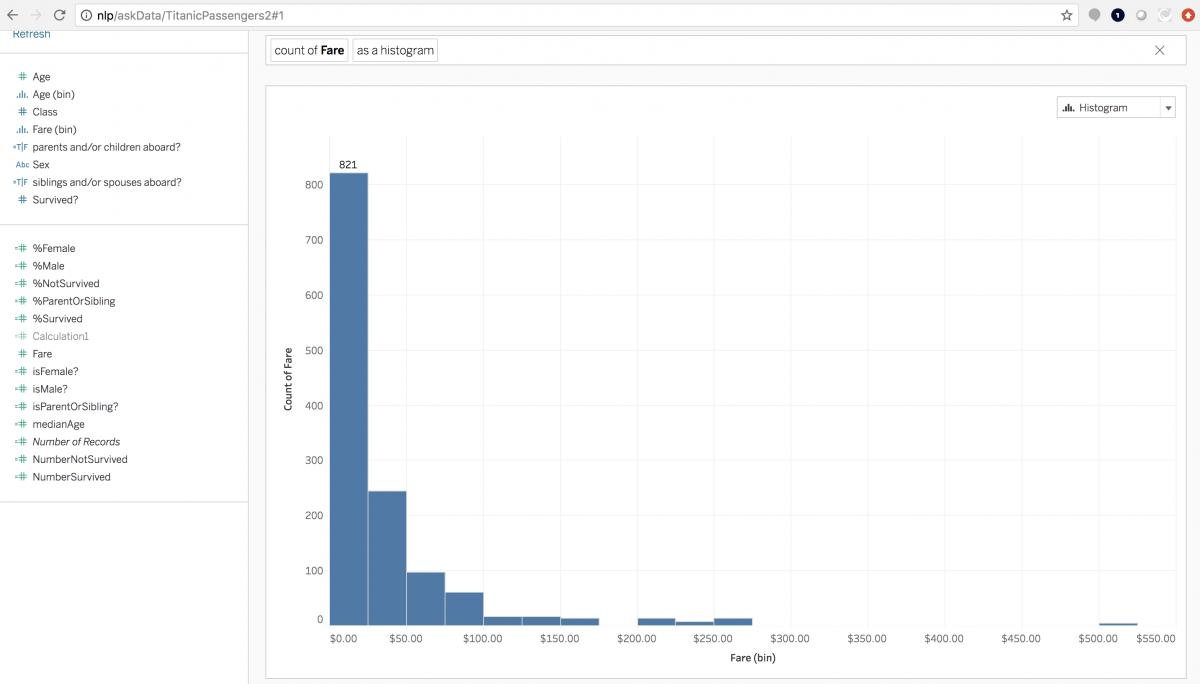
図 7: 「Fare as a histogram (料金をヒストグラムで)」という表現を、カスタムのビンサイズを使用して出力したビジュアライゼーション。
フィールドに意味のある独自の名前を付ける
エンドユーザーにデータソースをより理解してもらうため、つまりユーザーが必要な答えを「データに聞く」機能から得られる確率を高めるために、データソースのフィールド名を確認する必要があります。
理想的なユーザーエクスペリエンスを実現するために、次の手順を実行してください。
フィールド値の別名を作成する。Tableau Desktop では、分かりやすいフィールド名を別名とともに作成できます (例:「CustID」は「Customer ID」を示す)。これはデータキュレーションで推奨される標準です。「データに聞く」機能ではさらに一歩進んで、同義語を追加できます。たとえば、社内で「Customer ID」としているものを「Customer Number」として表記する場合があります。このような場合にユーザーの質問をサポートするために、いくつかの同義語を「データに聞く」機能に追加することが可能です。
属性を差別化する。データソースの属性に独自の名前を割り当てることで、「データに聞く」機能のユーザーエクスペリエンスを強化できます。表現が曖昧な場合、「データに聞く」機能ではデータのパターンにほぼ一致する (最大 1 文字異なる) 文字列を見つけます。これは文字列のファジーマッチとも呼ばれます。そして、「データに聞く」機能はそれらの複数の一致文字列をオプションとして表示します。下記の例 (図 8) では、「Sales (売上)」という語句を含む複数の属性がデータソースに存在しています。ただし、「sales」を入力するだけでは 3 つの属性しか一致しません。入力した語句「sales」は「Sales Foo」とは 2 文字以上異なるからです。
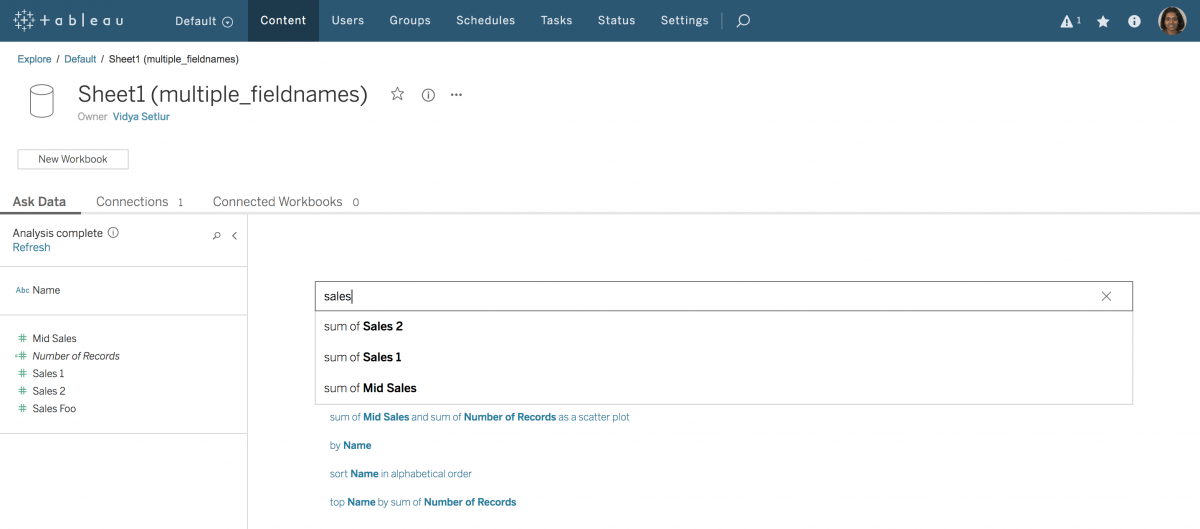
図 8
また、分析タスクで直感的に使用できるようにするために、そのデータソースの分野において意味論的に有効な属性名を付けることが推奨されます。たとえば、データソースで各レコードが地震を示している場合、「Number of Records (レコード数)」を「Number of Earthquakes (地震回数)」という名前に変更します。
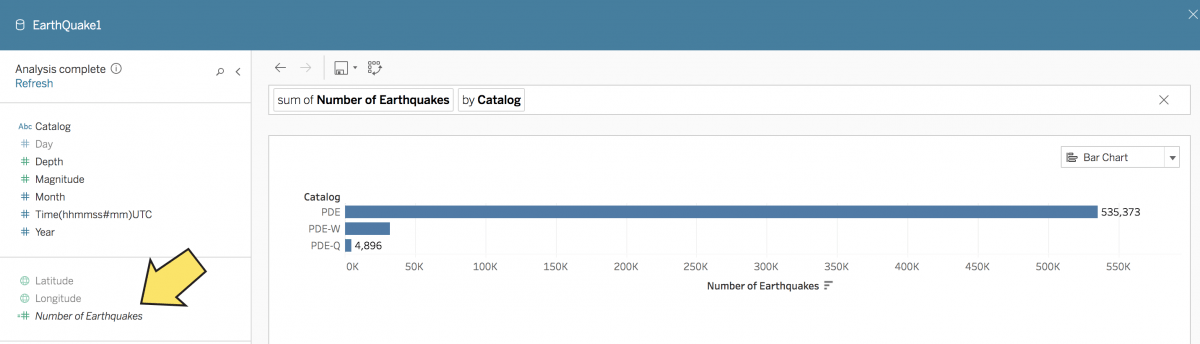
図 9
フィールド名をチェックする。「データに聞く」機能は、データソースのフィールドで値をフィルターします。「データに聞く」機能がデータフィールドを値として誤認識しないようにするために、フィールドを値として名前付けすることは避けます。また、パフォーマンスを犠牲にしないようにするために、「データに聞く」機能は、サポートされている分析的表現と重複するフィールドのインデックスを作成しません。たとえば、「Average (平均)」、「Sales in 2015 (2015 年の売上)」、「Most Products Sold (最も売れた製品)」などをフィールド名として使用しないようにします。
地理的フィールドをジオコーディングする。地理的役割のフィールドは、必ずデータ値をジオコーディングします。値が正しくジオコーディングされたフィールドは、「データに聞く」機能で地理的属性として認識され、データペインにアイコンで示されますそれらの属性は、「where are the highest fire fatalities? (火事による災害が最も大きかったのはどこ?)」といった質問をサポートします。つまり、システムが「where (どこ)」という要素を地図に示すものとして認識し、「County (国)」などの有効な地理的属性を推論します。

図 10
関連する計算フィールドを追加する
「データに聞く」機能はその場で計算を作成できないため、予想される計算を事前にデータソースに追加する必要があります。たとえば、[Base (Variable) (基本 (可変))] の最低基本給与と [Commission (Variable) (歩合 (可変))] の歩合合計を足す「Total Compensation (総報酬)」という名前の計算フィールドを作成すると、ユーザーは「what is the total compensation for each sales person? (各営業担当者の総報酬は?)」といった質問を入力できます(図 11 と 12)。

図 11: 計算フィールドを作成するには、[分析] > [計算フィールドの作成] を選択する。計算フィールドを編集するには、[データ] ペインで計算フィールドを右クリックして [編集] を選択する。
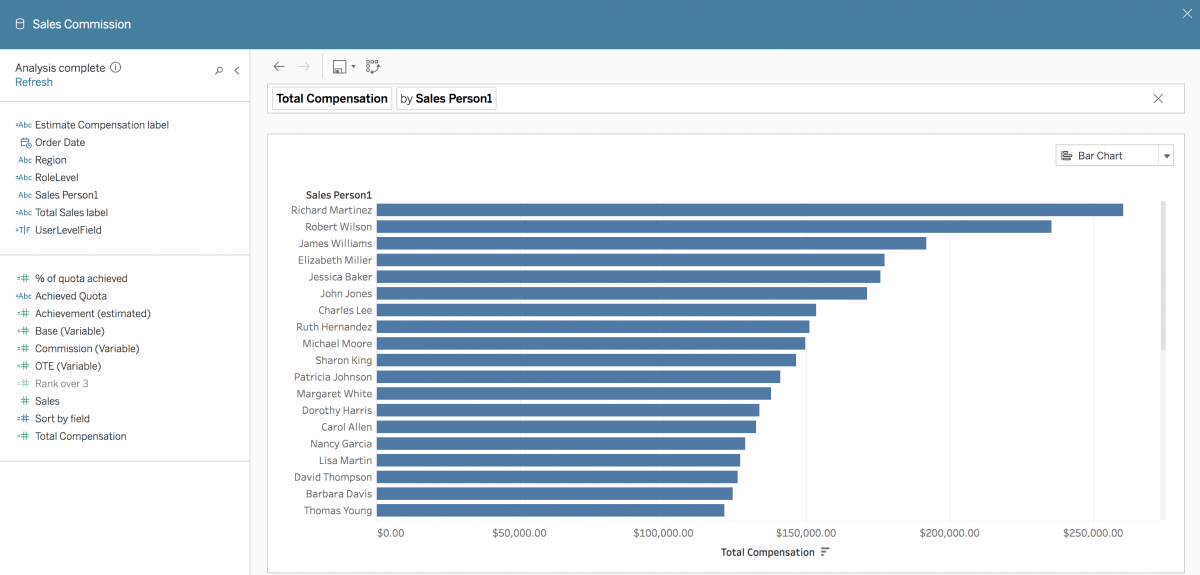
図 12: たとえば、[Base (Variable) (基本 (可変))] の最低基本給与と [Commission (Variable) (歩合 (可変))] の歩合合計を足す「Total Compensation (総報酬)」という名前の計算フィールドを作成すると、ユーザーは「what is the total compensation for each sales person? (各営業担当者の総報酬は?)」といった質問を入力できる
ユーザーが同義語を追加して強化する
[データに聞く] フィールドペインで、データソース内のフィールドの同義語を定義できます。たとえば、車の購入に関するデータソースを持っていて、[New Vehicle Model (新しい車両モデル)] というフィールドがあるとします。[New Vehicle Model (新しい車両モデル)] フィールドに、同義語として「vehicle purchased (購入された車両)」と「car (車)」を追加すると、「vehicles purchased by city (都市ごとの購入された車)」といった自然言語の質問をサポートできます。

図 13: 特定のデータフィールドの同義語を追加するには、データソースフィールドにカーソルを合わせ、下矢印をクリックし、[同義語の編集] を選択します。フィールド名の同義語を、コンマで区切って入力します。
データアクセスとガナバンスを可能にする
「データに聞く」機能には、Tableau Server または Online と同じセキュリティおよびガバナンス対策が採用されています。以下のセクションでは、「データに聞く」機能で認証済みデータソースを使用する方法と、組織全体について「データに聞く」機能へのアクセスを制御する方法について説明します。
役割とパーミッションを設定する
「データに聞く」機能向けにデータを整理したら、この機能にアクセスできるユーザーを制御できます。「データに聞く」機能を使用するには、ユーザーは Creator または Explorer の役割が必要であり、Tableau Server または Online の Web 作成へのアクセス権が必要です。Tableau Server 管理者は、サイトレベルでパーミッションを指定して、Web 作成機能にアクセスできるユーザーを指定できます (図 14 参照)。アナリストおよびビジネスユーザーは、データソースを素早く簡単に探索し、有意義なインサイトをその場で見つけることができる方法として、「データに聞く」機能の価値を認識します。
Web 作成のパーミッションの詳細について確認してください。
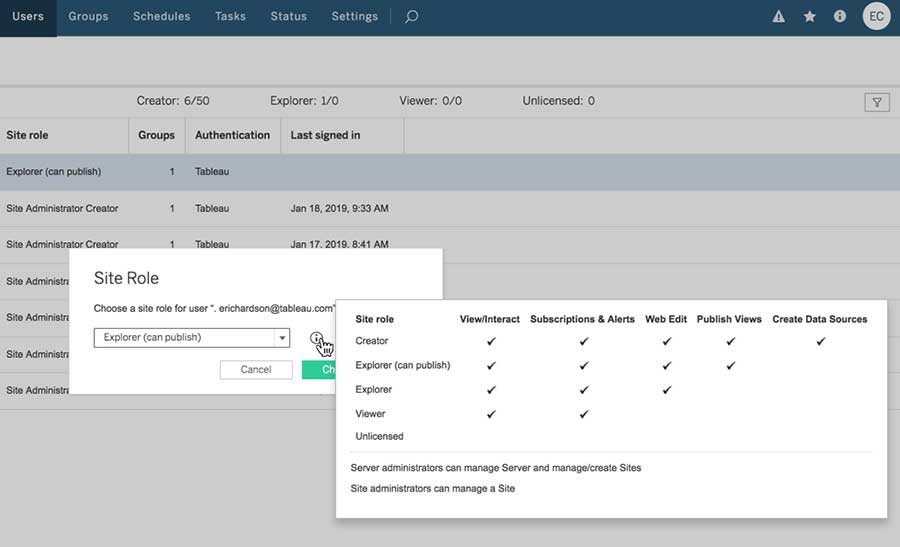
図 14: サイトレベルでパーミッションを指定して、Web 作成機能 (「データに聞く」機能を含む) にアクセスできるユーザーを指定する。
認証済みデータソースを確認する
ユーザーは Tableau Server または Online でデータソースを認証し、そのデータソースが信頼できること、および整理されていることを示すことができます。これは機能固有の認証ではありません。「データに聞く」機能に固有の認証はありません。ただし、具体的に 1 つのデータソースに関して「データに聞く」機能を無効化したい場合、ユーザーは Tableau Server ユーザーインターフェイスのデータソース設定で無効化できます (図 15 と 16 を参照)。

図 15

図 16: 必要な場合は、Tableau Server または Online のデータソース詳細セクションで特定のデータソースに関して「データに聞く」機能を無効化できる。
「データに聞く」機能により、組織の全員がデータについて質問できる可能性が開かれます。データ整理に関するこれらのガイドラインは、自然言語を使用した理想的なユーザーエクスペリエンスを実現するデータ準備に役立ちます。